Using a TMDb movie data set containing properties of movies released between 1960 and 2015, I explored what are related to financial success of movies, with visualizations.
In assessing financial success, I used Return on Investment (ROI), a measure commonly used in describing profitability. It is calculated by: ROI = (gross revenue - cost)/cost. Of the properties, I was most interested in budget, genres, and vote scores. Specifically, I investigated:
- Did high budget movies achieve high ROI?
- Did specific genres lead to high ROI?
- Did high score movies achieve high ROI?
The work process was:
- Data overview
- Data wrangling
- Univariate exploration
- Q1: Did high budget movies achieve high ROI?
- Q2: Did specific genres lead to high ROI?
- Q3: Did high score movies achieve high ROI?
- Conclusions (Summary, Limitations)
I will walk through the process here. You can see code and all details in my GitHub.
Data overview
After loading the data set, I looked at a couple of fundamental aspects.
df.head()
| id | imdb_id | popularity | budget | revenue | original_title | cast | homepage | director | tagline | keywords | overview | runtime | genres | production_companies | release_date | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 135397 | tt0369610 | 32.985763 | 150000000 | 1513528810 | Jurassic World | Chris Pratt|Bryce Dallas Howard|Irrfan Khan|Vi... | http://www.jurassicworld.com/ | Colin Trevorrow | The park is open. | monster|dna|tyrannosaurus rex|velociraptor|island | Twenty-two years after the events of Jurassic ... | 124 | Action|Adventure|Science Fiction|Thriller | Universal Studios|Amblin Entertainment|Legenda... | 6/9/15 | 5562 | 6.5 | 2015 | 1.379999e+08 | 1.392446e+09 |
| 1 | 76341 | tt1392190 | 28.419936 | 150000000 | 378436354 | Mad Max: Fury Road | Tom Hardy|Charlize Theron|Hugh Keays-Byrne|Nic... | http://www.madmaxmovie.com/ | George Miller | What a Lovely Day. | future|chase|post-apocalyptic|dystopia|australia | An apocalyptic story set in the furthest reach... | 120 | Action|Adventure|Science Fiction|Thriller | Village Roadshow Pictures|Kennedy Miller Produ... | 5/13/15 | 6185 | 7.1 | 2015 | 1.379999e+08 | 3.481613e+08 |
| 2 | 262500 | tt2908446 | 13.112507 | 110000000 | 295238201 | Insurgent | Shailene Woodley|Theo James|Kate Winslet|Ansel... | http://www.thedivergentseries.movie/#insurgent | Robert Schwentke | One Choice Can Destroy You | based on novel|revolution|dystopia|sequel|dyst... | Beatrice Prior must confront her inner demons ... | 119 | Adventure|Science Fiction|Thriller | Summit Entertainment|Mandeville Films|Red Wago... | 3/18/15 | 2480 | 6.3 | 2015 | 1.012000e+08 | 2.716190e+08 |
| 3 | 140607 | tt2488496 | 11.173104 | 200000000 | 2068178225 | Star Wars: The Force Awakens | Harrison Ford|Mark Hamill|Carrie Fisher|Adam D... | http://www.starwars.com/films/star-wars-episod... | J.J. Abrams | Every generation has a story. | android|spaceship|jedi|space opera|3d | Thirty years after defeating the Galactic Empi... | 136 | Action|Adventure|Science Fiction|Fantasy | Lucasfilm|Truenorth Productions|Bad Robot | 12/15/15 | 5292 | 7.5 | 2015 | 1.839999e+08 | 1.902723e+09 |
| 4 | 168259 | tt2820852 | 9.335014 | 190000000 | 1506249360 | Furious 7 | Vin Diesel|Paul Walker|Jason Statham|Michelle ... | http://www.furious7.com/ | James Wan | Vengeance Hits Home | car race|speed|revenge|suspense|car | Deckard Shaw seeks revenge against Dominic Tor... | 137 | Action|Crime|Thriller | Universal Pictures|Original Film|Media Rights ... | 4/1/15 | 2947 | 7.3 | 2015 | 1.747999e+08 | 1.385749e+09 |
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10866 entries, 0 to 10865 Data columns (total 21 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 10866 non-null int64 1 imdb_id 10856 non-null object 2 popularity 10866 non-null float64 3 budget 10866 non-null int64 4 revenue 10866 non-null int64 5 original_title 10866 non-null object 6 cast 10790 non-null object 7 homepage 2936 non-null object 8 director 10822 non-null object 9 tagline 8042 non-null object 10 keywords 9373 non-null object 11 overview 10862 non-null object 12 runtime 10866 non-null int64 13 genres 10843 non-null object 14 production_companies 9836 non-null object 15 release_date 10866 non-null object 16 vote_count 10866 non-null int64 17 vote_average 10866 non-null float64 18 release_year 10866 non-null int64 19 budget_adj 10866 non-null float64 20 revenue_adj 10866 non-null float64 dtypes: float64(4), int64(6), object(11) memory usage: 1.7+ MB
The data set had 10866 records with 21 columns. Some columns, like ‘cast’ and ‘genres’, contained multiple values separated by pipe characters. With regard to budget and revenue, the data set had both original and inflation adjusted value column. I chose to use the inflation adjusted ones.
Data wrangling
In this step, I dealt with:
- Duplicates
- Missing values
- Unused columns
- Incorrect values
- Extraction of a variable of interest (i.e., ROI)
- Data type
- Outliers
Duplicates
First of all, I examined if there were any duplicate records by checking for (1) duplicate id values, and (2) records with the same ‘title’, ‘director’, ‘release_year’, and ‘runtime’.
Based on ‘id’
df[df.duplicated(['id'], keep = False)]
| id | imdb_id | popularity | budget | revenue | original_title | cast | homepage | director | tagline | keywords | overview | runtime | genres | production_companies | release_date | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2089 | 42194 | tt0411951 | 0.59643 | 30000000 | 967000 | TEKKEN | Jon Foo|Kelly Overton|Cary-Hiroyuki Tagawa|Ian... | NaN | Dwight H. Little | Survival is no game | martial arts|dystopia|based on video game|mart... | In the year of 2039, after World Wars destroy ... | 92 | Crime|Drama|Action|Thriller|Science Fiction | Namco|Light Song Films | 3/20/10 | 110 | 5.0 | 2010 | 30000000.0 | 967000.0 |
| 2090 | 42194 | tt0411951 | 0.59643 | 30000000 | 967000 | TEKKEN | Jon Foo|Kelly Overton|Cary-Hiroyuki Tagawa|Ian... | NaN | Dwight H. Little | Survival is no game | martial arts|dystopia|based on video game|mart... | In the year of 2039, after World Wars destroy ... | 92 | Crime|Drama|Action|Thriller|Science Fiction | Namco|Light Song Films | 3/20/10 | 110 | 5.0 | 2010 | 30000000.0 | 967000.0 |
Two records were detected, identical for all the variables. So, an extra was deleted.
Based on ‘title’, ‘director’, ‘release_year’, and ‘runtime’
df[df.duplicated(['original_title', 'director', ], keep = False)]\
[['original_title', 'director', 'release_year', 'runtime']].sort_values(by=['original_title'])
| original_title | director | release_year | runtime | |
|---|---|---|---|---|
| 1400 | 9 | Shane Acker | 2009 | 79 |
| 6514 | 9 | Shane Acker | 2005 | 11 |
| 4337 | Bottle Rocket | Wes Anderson | 1994 | 13 |
| 8547 | Bottle Rocket | Wes Anderson | 1996 | 91 |
| 4451 | Frankenweenie | Tim Burton | 2012 | 87 |
| 7943 | Frankenweenie | Tim Burton | 1984 | 29 |
| 4063 | Madea's Family Reunion | Tyler Perry | 2002 | 0 |
| 6701 | Madea's Family Reunion | Tyler Perry | 2006 | 110 |
| 5202 | Saw | James Wan | 2003 | 9 |
| 7011 | Saw | James Wan | 2004 | 103 |
The output shows that some movies have another movie with the same title/director/release_year. With online search, I learned that this happens sometimes; e.g., a director makes a ‘mini’ version before the full scale. So I kept all the records.
Missing values
The ‘genre’ had only 23 nulls, but there were many records with 0 value for the budget and/or revenue. I had to remove all the records that belonged to any of the following:
- null for ‘genre’
- 0 for ‘budget_adj’
- 0 for ‘revenue_adj’
Incorrect values
As a minimum effort to ensure correctness of budget and revenue values, I inspected data points at both ends (the lowest and highest).
Top budget movie
df[df['budget_adj'] == df['budget_adj'].max()]
| id | budget | revenue | original_title | genres | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|
| 2244 | 46528 | 425000000 | 11087569 | The Warrior's Way | Adventure|Fantasy|Action|Western|Thriller | 6.4 | 2010 | 425000000.0 | 11087569.0 |
Although the above says that ‘The Warrior’s Way’ is the highest budget movie by 425 million, online search revealed that the budget of it is 42.5 million. After this correction, the highest budget became $368 millon of ‘Pirates of the Caribbean: On Stranger Tides,’ which is correct.
Top revenue movie
‘Avartar’ came out as the highest revenue movie, and online search confirmed it.
Bottom budget movie
I displayed several lowest budget movies, and got puzzled with extremely low values like $1, $50, or ‘$100. I did online search and found that:
- ‘Primer (2004)’ is considered as the lowest budget movie (https://en.wikipedia.org/wiki/Low-budget_film)
- Many of the low budget values are wrong; for example, the budget of ‘Lost & Found (1999)’ is $30 million, not $1.3, ‘Joyful Noise (2012)’, $25 millon, not $23, ‘Weekend (2011)’, $0.14 millon, not $7755, etc. With the above findings, I inclined to believe that $8081, budget of ‘Primer (2004)’, should be the lowest. I removed movies whose budget was lower than it.
Bottom revenue movie
Again, online search made me distrust data points whose revenue was lower than the revenue of ‘Best Man Down’ ($1840.6). They were removed.
Data type
df.loc[:, 'genres'] = df['genres'].str.strip().str.split("|")
Values of ‘genres’ transformed from string to list, e.g., Action|Adventure|Science Fiction –> [Action, Adventure, Science Fiction], for convenience in later analysis.
Outliers
Fundamentally, I identified records that might inhibit finding a general direction by looking into each variable, and removed them.
Budget
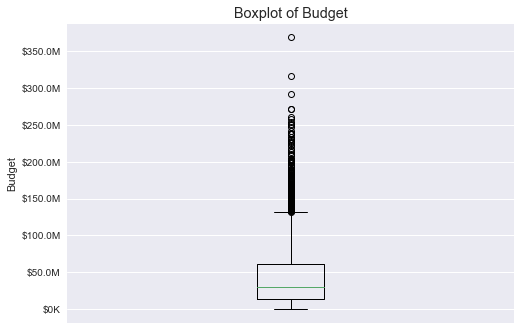
Several records on the top stand out, but I considered them still continuous.
Number of movies by genres
For each genre, I calculated the number of movies involving it.
# Generate a long format dataframe
df_long = df.explode('genres')
# Count the number of inclusion of each genre.
df_long['genres'].value_counts()
Drama 1746 Comedy 1347 Thriller 1197 Action 1078 Adventure 746 Romance 660 Crime 649 Science Fiction 518 Horror 460 Family 423 Fantasy 393 Mystery 344 Animation 200 Music 134 History 129 War 119 Western 52 Documentary 34 Foreign 13 TV Movie 1 Name: genres, dtype: int64
I noted that the bottom four genres are involved by a quite small number of movies, less than 100. The number of Western-involved movies is fewer than the half of War-involved movies. I decided to exclude these genres.
Vote scores
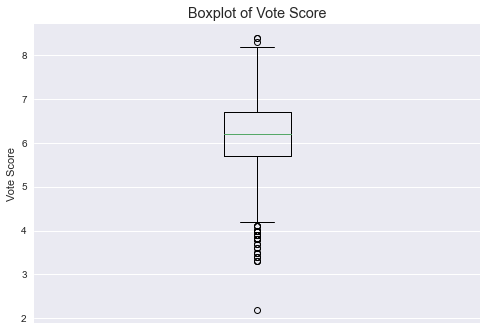
Judging that it is so far away from the nearest, I removed the data point with the lowest value.
ROIs
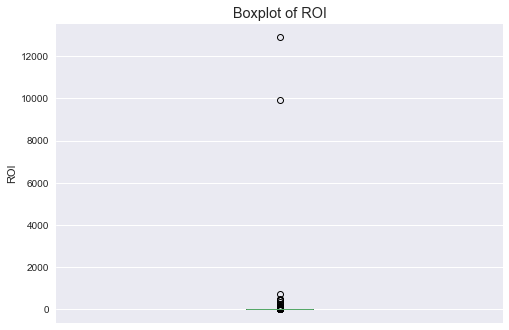
The top two data points were considered too far away that I removed them.
To sum up, the data wrangling step removed 7138 records leaving 3728 records in total. The largest removal, 7011 records, was due to value missingness.
Univariate Exploration
I surveyed the variables, budget, ROI, genres, and vote score, individually, before looking at relationships between them.
Budget
The budget is long right tailed, ranging from $8081 to $368 millon (redline for median).
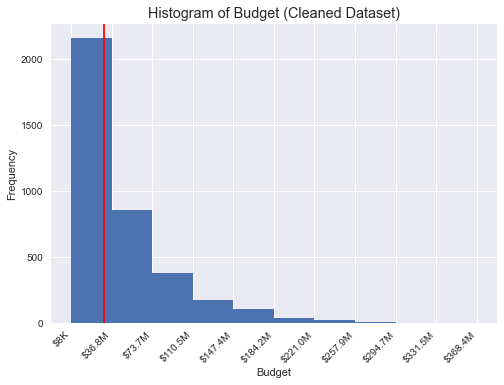
For later analysis, I categorized values into four groups as follows.
qt = df['budget_adj'].quantile([0.25, 0.5, 0.75])
def binning4(x):
if x < qt[0.25]:
return "Low"
elif (x >= qt[0.25]) & (x < qt[0.5]):
return "Moderate"
elif (x >= qt[0.5]) & (x < qt[0.75]):
return 'Little High'
elif x >= qt[0.75]:
return 'High'
df['budget_level'] = df['budget_adj'].apply(binning4)
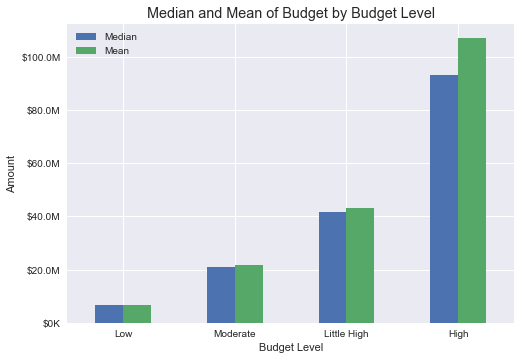
ROI
The ROI column is extremely long tailed, ranging from -1 to 699. More than 3500 out of 3728 fall into between -1 and 22.3 as shown below.
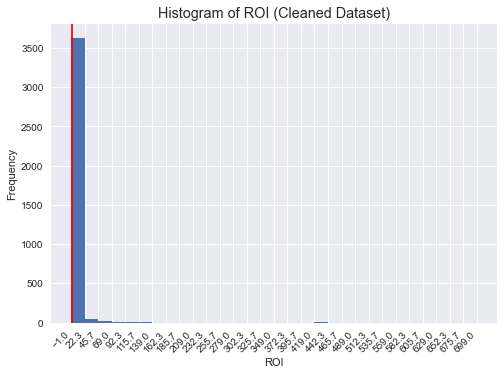
I categorized the ROI in the same way to the budget.
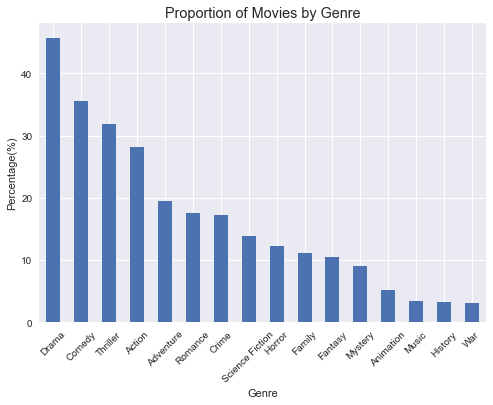
Genres
I plotted the percentage of movies involving each genre. It shows that almost the half of movies involved ‘Drama’, and ‘Comedy’ is the next most involved genre by about %35.
Vote score
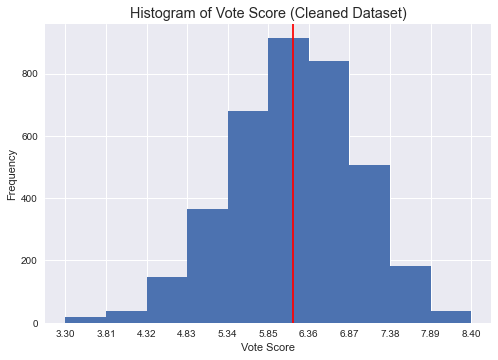
The vote score seems normally distributed (mean = 6.2, SD = 0.8).
Q1: Did high budget movies achieve high ROI?
I plotted a scatter plot (top), ROI distribution by budget level (bottom-left), and median value by budget level (bottom right).
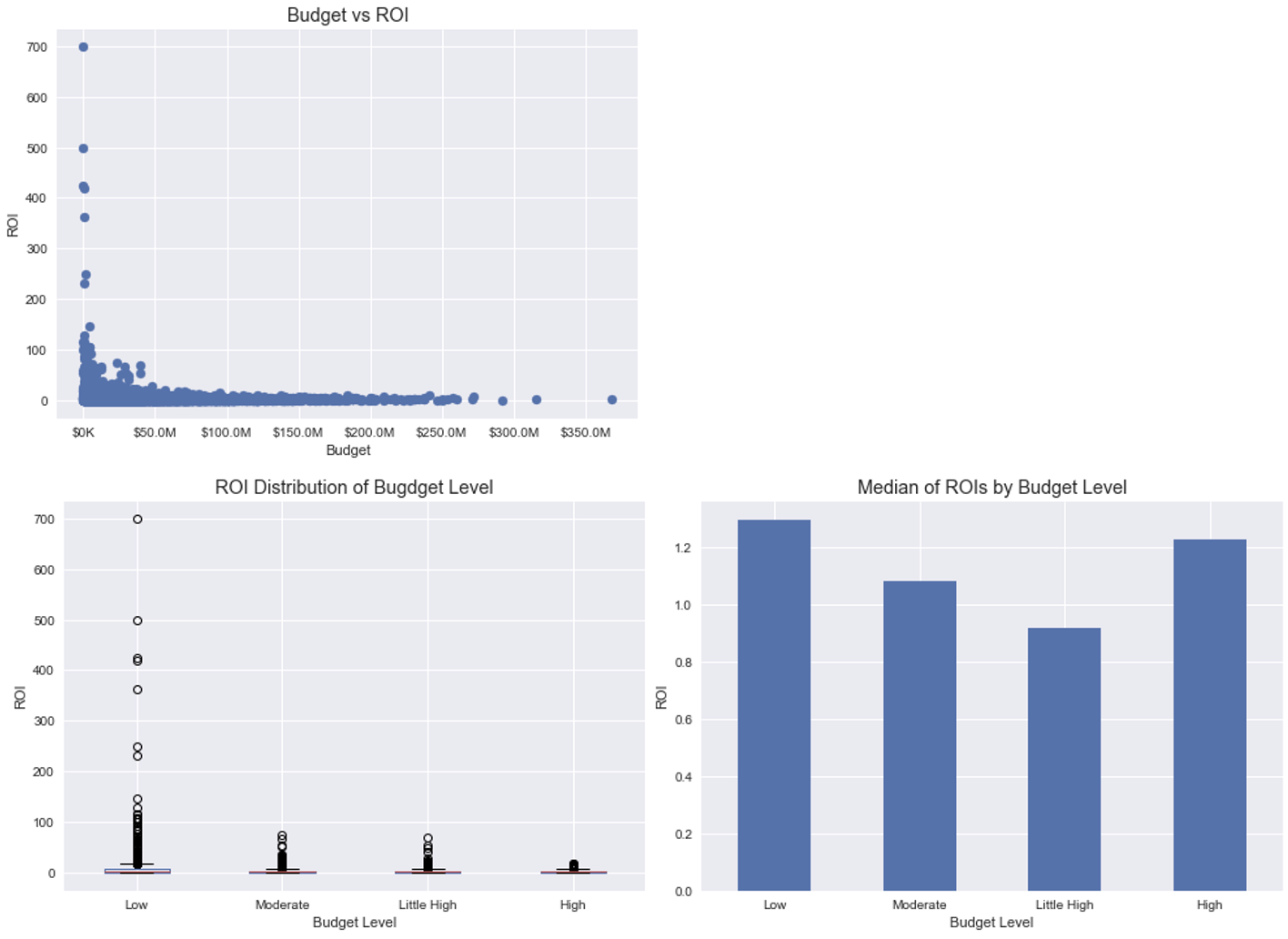
It is hard to find a relationship in the scatter plot. But, the boxplot by the budget level shows that ROI values of low budget movies span a wide range, up to 500, the largest ROI value in the dataset. The larger budget groups have the narrower spread of ROIs. As well, the comparison of median values shows that the low and high budget levels have a little higher median values than the moderate and little high budget levels.
Meanwhile, I created a contigency table and plotted it as below.
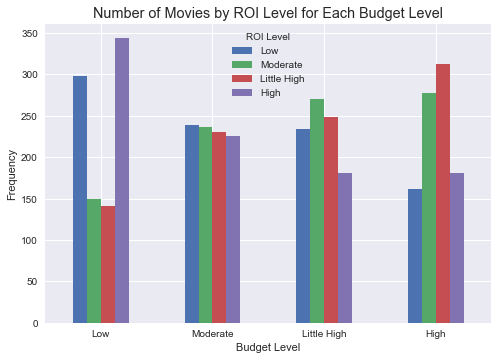
It is found that low budget movies achieve the low and high level ROIs more frequently than the moderate and little high level ROIs. As opposed to it, high budget movies obtain the moderate and little high level ROIs more frequenlty.
Q2: Did specific genres lead to high ROI?
To compare ROIs between the genres, I calculated two types of means:
- Simple mean: Simply add up all ROIs and divide it with the total number of movies involving that genre.
- Weighted mean: Assign weights based on the number genre types involved in a movie. A ROI is multiplied by 1/number_of_genres and the sum is divided by the sum of 1/number_of_genres values.
For example, let’s assume we have a long format dataframe of three movies as below:
| id | genre | ROI | number of genres |
|---|---|---|---|
| 1 | drama | 3 | 2 |
| 1 | comedy | 3 | 2 |
| 2 | comedy | 5 | 1 |
| 3 | drama | 2 | 1 |
Simple means are:
- drama, (3+2) / 2 = 2.5
- comedy, (3+5) / 2 = 4
Weighted means are:
- drama, (3x1/2+2x1/1) / (1/2+1) = (1.5+2) / 1.5 = 2.33
- comedy, (3x1/2+5x1/1) / (1/2+1) = (1.5+5) / 1.5 = 4.33
The below shows results of the two methods. The results are not exactly the same (especailly, ‘Horror’ has a larger difference between the two results than other genrens), but order is the same.
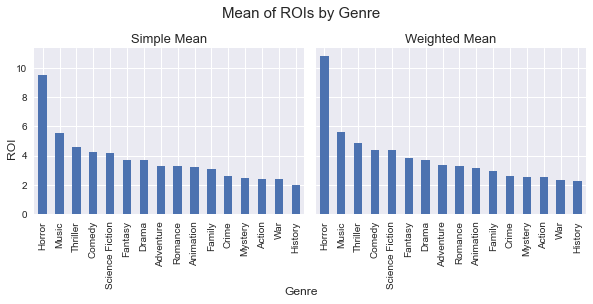
The results hints that ‘Horror’ tends to bring quite larger ROIs compared to the others. The next profitable genre is ‘Music’ by round 4 or 5 smaller ROI than Horror. ROI values gradually decrease after ‘Music, and thus the difference between ‘Music’ and ‘History’ is only about 3.5.
Although I believe that I obtained an acceptable finding with my approach, it is a shame that effect of combination of genres was not studied. This issue will be discussed a bit more in ‘Limitations’ section at the end.
Q3: Did high score movies achieve high ROI?
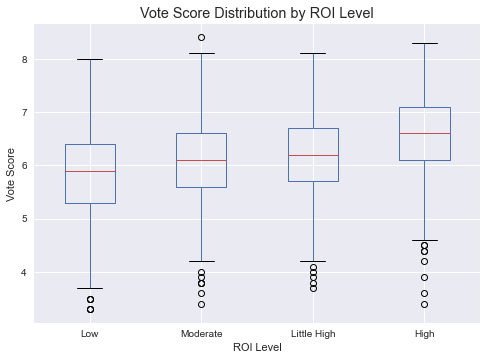
The chart shows that the high ROI level tends to bring a little higher median of vote scores (0.4 higher than the little high level, and 0.7 than the low level).
Conclusions
Summary
With the exploration, I found association between 1) budget size and ROI, 2) genres and ROI, and 3) vote average score and ROI. To sum up:
- I found contrary behavior between the low and high budget groups, in terms of their ROIs. Low budget movies are more likely to be big fail or big success, and high budget movies tend to end up in the middle. This behavior seems a consequence. Considering different capabilities in reaching the audience and the definition of ROI, this behavior seems natural.
- The genre type that resulted in the highest ROI on average is ‘Horror’, and the smallest ROI, ‘History’, among 17 genre types (excluding ‘Western’, ‘Documentary’, ‘Foreign’, and ‘TV Movie’).
- It was found that the higher ROI level group tend to associate with higher mean of the vote average.
Based on these findings, it is considered that production of low budget, horror movies that receive high score from the audience is likely to lead to high ROI.
Limitations
The exploration has several limitations as follows:
- Only about a third of the original datapoints were used in the analysis, since the rest had missing or outlying values. As well, there was no further work to check if any pattern exists in missing or outlying values.
- In finding association between genres and ROIs, potential effect of genre combination was not explored, and it makes the result somewhat insecure. For instance, let’s assume the following dataset of four movies:
| id | genres | ROI |
|---|---|---|
| 1 | Drama | 2 |
| 2 | Drama, Family | 8 |
| 3 | Drama, Horror | 8 |
| 4 | Family | 2 |
Calculation of weighted means (Drama, 5; Family, 4; Horor, 8) indicates that the highest ROI genre is Horror. However, it is not sure if this is the power of the Horror genre or result of pairing with Drama, since it does not have movies that involve only Horror.